Investigating the branching improvements from Part 2
Modern CPUs use branch prediction to speculatively execute instructions, but when predictions fail, the performance penalty can be significant. Understanding and optimizing for branch behavior is crucial for high-performance networking code.
This video serves as good background material for those unfamiliar with the topic.
A short explanation, with my current understanding of the topic, is as follows:
- The overhead for a branch is generally small compared to the cost of a missed branch prediction.
- Most conditional statements based on random data (rather than simple arithmetic operations) will cause branches that are likely to be mispredicted
- This occurs because it’s much less likely that the next instruction will access the same memory location or adjacent memory
Please reach out if you believe anything written here is incorrect. I’ve been actively learning and applying these concepts the last few months, so feedback is appreciated.
TL; DR
Note that these are not all exactly sequential, or building on each other in order.
| Optimization Stage | Description | Sender Branches | Sender Misses | Sender Miss % | Receiver Branches | Receiver Misses | Receiver Miss % |
|---|---|---|---|---|---|---|---|
| Initial (Part 2 End) | Baseline with stream-based serialization | 4,731,433 | 10,029 | 0.21% | 1,403,209 | 16,642 | 1.19% |
| 0. Remove Print & RNG | Eliminated printf statements and random number generation |
- | - | - | 377,933 | 4,137 | 1.09% |
| 1. Direct Bit Manipulation | Replaced FixedBufferStream with direct manipulation |
4,646,337 | 8,356 | 0.18% | 682,833 | 13,723 | 2.01% |
| 1. Serialization Refinement | Further serialization optimizations | 391,758 | 7,316 | 1.87% | - | - | - |
| 2. Unsafe Enum Conversion | Used @enumFromInt instead of std.meta.intToEnum |
~240,000 | ~4,000 | ~1.67% | - | - | - |
| 3. Memory Operations | Switched from std.mem.copyForwards to @memcpy/@memmove |
886,572 | 7,639 | 0.86% | - | - | - |
| Larger Packets (10KB) | Increased packet size from 1KB to 10KB | 58,401 | 1,797 | 3.08% | 29,060 | 1,034 | 3.56% |
| Branch Hints | Added @branchHint(.likely) for common paths |
314,253 | 5,988 | 1.91% | 259,331 | 4,456 | 1.72% |
| Jump Table | Function pointer table instead of switch statements |
322,202 | 6,355 | 1.97% | 266,677 | 4,464 | 1.67% |
| Current + ReleaseSafe | All optimizations + compiler flags (10KB packets) | 19,540 | 949 | 4.86% | 8,915 | 1,005 | 11.27% |
| Original + ReleaseSafe | Part 2 baseline + compiler optimization flags | 90,067 | 3,773 | 4.19% | 54,717 | 2,164 | 3.95% |
Key Insights
- Biggest single impact: Increasing packet size from 1KB to 10KB (~75% branch miss reduction); at a certain point most branching and misses will come from system calls, and then your only option is to find ways to utilize those system calls less frequently
- Compilers are good at their job: Compiler optimization flags (
ReleaseSafe) provided massive improvements with minimal effort - Diminishing returns: Manual micro-optimizations showed progressively smaller gains or inconsistent gains
- The meta-lesson: Always measure with realistic data (production data, production build flags) before optimizing
Recap of zudp Branching
At the beginning our sender path had the following:
Performance counter stats for './zig-out/bin/zudp -- --mode send':
4,731,433 branches:u
10,029 branch-misses:u # 0.21% of all branches
0.530626336 seconds time elapsed
0.000000000 seconds user
0.006419000 seconds sys
And the receiver had:
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
1,403,209 branches:u
16,642 branch-misses:u # 1.19% of all branches
1.071376226 seconds time elapsed
0.002953000 seconds user
0.013757000 seconds sys
Optimization Techniques
0. Print statements and RNG
The first obvious change was removing print statements as well as the RNG (used for randomly dropping packets to test the ‘sliding window’ ACK behaviour).
Under the hood printf like functions are formatting input strings character by character. This means that we have branching for all kinds of things; format specifiers (%d, %s, etc.), the dynamic type handling that happens to support the various types that can all match a certain format specifier (%d should support any digit type).
There would also be buffering and conditionals for checking if the buffer is full, plus branching for the actual system call to write to stdout/stderr which has its own conditionals for error conditions/partial writes/etc.
On top of that, we were deserializing each packet and then printing it immediately, which is essentially context switching from one kind of work to another. If we’d instead buffered some amount of deserialized packets before printing we would be allowing the CPU to keep a cleaner branch history (longer periods of the same kind of work), keep the deserializing function in the instruction cache for longer, and when we got around to doing the printing we’d have a better chance of our print branches hitting already fetched memory since we’d be printing many in a row.
The RNG branching should be obvious as to why it could cause misses. We’re generating a random number in some range, and then seeing if it matches the % threshold set for dropping a packet. If we’re deciding to drop 1% of packets then on average 1% of these branches should be mispredicted.
After removing the packet print and RNG code we end up with the receiver looking like this:
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
377,933 branches:u
4,137 branch-misses:u # 1.09% of all branches
2.334070233 seconds time elapsed
0.001466000 seconds user
0.002930000 seconds sys
1. Replacing Stream-Based Serialization and Deserialization
Our initial implementation used Zig’s FixedBufferStream for packet deserialization, which introduced multiple internal branches per field read:
The problem with FixedBufferStream is that we copy the entire packet from the wire into the stream buffer, but the reader doesn’t know this. The reader still requires a readNoEof call for every field read from the buffer.
This creates a conditional if (bytes_read < buf.len) return error.EndOfStream; for every incoming packet. Even if the last 99 calls to readNoEof correctly predicted we won’t hit EOF, the 100th call might be mispredicted.
This inefficiency exists despite knowing we have all the data from the socket and knowing the exact packet structure for reading precise data amounts for each field.
By switching to direct bit manipulation, we can eliminate these branch points while maintaining the same functionality.
As expected, this change mostly impacted the total # of branches.
Receiver:
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
682,833 branches:u
13,723 branch-misses:u # 2.01% of all branches
3.238406723 seconds time elapsed
0.001842000 seconds user
0.015572000 seconds sys
Sender:
Performance counter stats for './zig-out/bin/zudp -- --mode send':
4,646,337 branches:u
8,356 branch-misses:u # 0.18% of all branches
1.140326874 seconds time elapsed
0.006188000 seconds user
0.000913000 seconds sys
Making another change to the serialization functions again had a decent impact on branches but not misses (see the perf output in section 3 first):
Performance counter stats for './zig-out/bin/zudp -- --mode send':
391,758 branches:u
7,316 branch-misses:u # 1.87% of all branches
1.350311334 seconds time elapsed
0.001164000 seconds user
2. Using Unsafe Enum Conversion
Replacing std.meta.intToEnum with @enumFromInt when we need to switch on the packet kind eliminated error checking branches when we’re okay with making assumptions about the validity of the input. The version of Zig we’re using has std.intFromEnum, which actually calls meta.intToEnum. That function has branches for safety reasons. See here.
The perf CLI output wasn’t captured at this stage (we only have the screenshot in the last post), but at this point we’re down to roughly 240k branches with still around 4k misses.
3. Memory Operations
Switching from std.mem.copyForwards (deprecated) to @memcpy or @memmove reduced branch calls overall but didn’t have much impact on misses. copyForwards has a loop over the source bytes to copy them into the destination, so it has the for loop condition, bounds checking for the index into destination, and more. The built-ins have no safety checks for things like overlapping arrays or insufficient space. They actually explicitly set the runtime safety to false.
copyForwards likely doesn’t create many misses because the branches are predicted correctly, we’re copying sequential data from one location to another but also a relatively small amount of memory in each call. The @memcpy and @memmove built-ins have underlying assembly implementations that have been optimized to avoid branching.
For the sender we now have:
Performance counter stats for './zig-out/bin/zudp -- --mode send':
886,572 branches:u
7,639 branch-misses:u # 0.86% of all branches
0.521193266 seconds time elapsed
0.000000000 seconds user
0.004463000 seconds sys
Additional Optimizations
1. Larger packets
At this point, most of the sources of remaining branches and branch misses are somewhat unavoidable. They’re from system calls such as sendto, recvfrom, or the reading of the file that we use as the data for our packets. However, we can reduce the overall # of these branches, and misses, by reducing the overall # of packets we have to send. We’ll do this by increasing the allowed data size for our packets.
Note: it’s important to remember here that there will be buffer sizes at the network stack level. These limits determine the maximum amount of data that can be transferred between the underlying hardware layer and system socket. On most operating systems you can modify these buffer sizes for UDP sockets within your application. At the moment the file we’re using for testing is only a few hundred KB so we won’t bother. Setting the packet size too large or sending too many packets at once could mean that data is either lost on the receiver or send calls on the sender are blocked.
At the moment, in build_window, we’re limiting ourselves to roughly 1KB of data within each packet:
fn build_window(window: *packet.PacketWindow, f: std.fs.File) !void {
var buf: [1024 - 21]u8 = undefined;
while (true) {
if (!window.can_push()) {
return;
}
const bytesRead = try f.read(buf[0..]);
if (bytesRead == 0) {
return error.ErrorEoT; // EOF reached
}
window.push_data(.{ .src = sender.in, .dest = receiver.in, .seq = @intCast(window.next_seq), .data = buf[0..bytesRead] }) catch break;
}
}
Lets see what branches/misses for the sender and receiver look like if we increase this to 10KB.
Sender:
Performance counter stats for './zig-out/bin/zudp -- --mode send':
58,401 branches:u
1,797 branch-misses:u # 3.08% of all branches
0.517200732 seconds time elapsed
0.001330000 seconds user
0.000000000 seconds sys
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
29,060 branches:u
1,034 branch-misses:u # 3.56% of all branches
1.175298719 seconds time elapsed
0.001384000 seconds user
0.000000000 seconds sys
It’s important to remember that this change also impacts the amount of memory we allocate on the sender!
This creates a trade-off between memory usage and CPU performance. Larger packets mean more memory allocated per packet window, but potentially significant CPU savings. For applications that are CPU-bound rather than memory-bound, this 75% reduction in branch misses likely makes the extra memory allocation worthwhile.
2. Switch Statements
The remaining standout Zig function calls that are producing branch misses are still our serialization and deserialization functions.
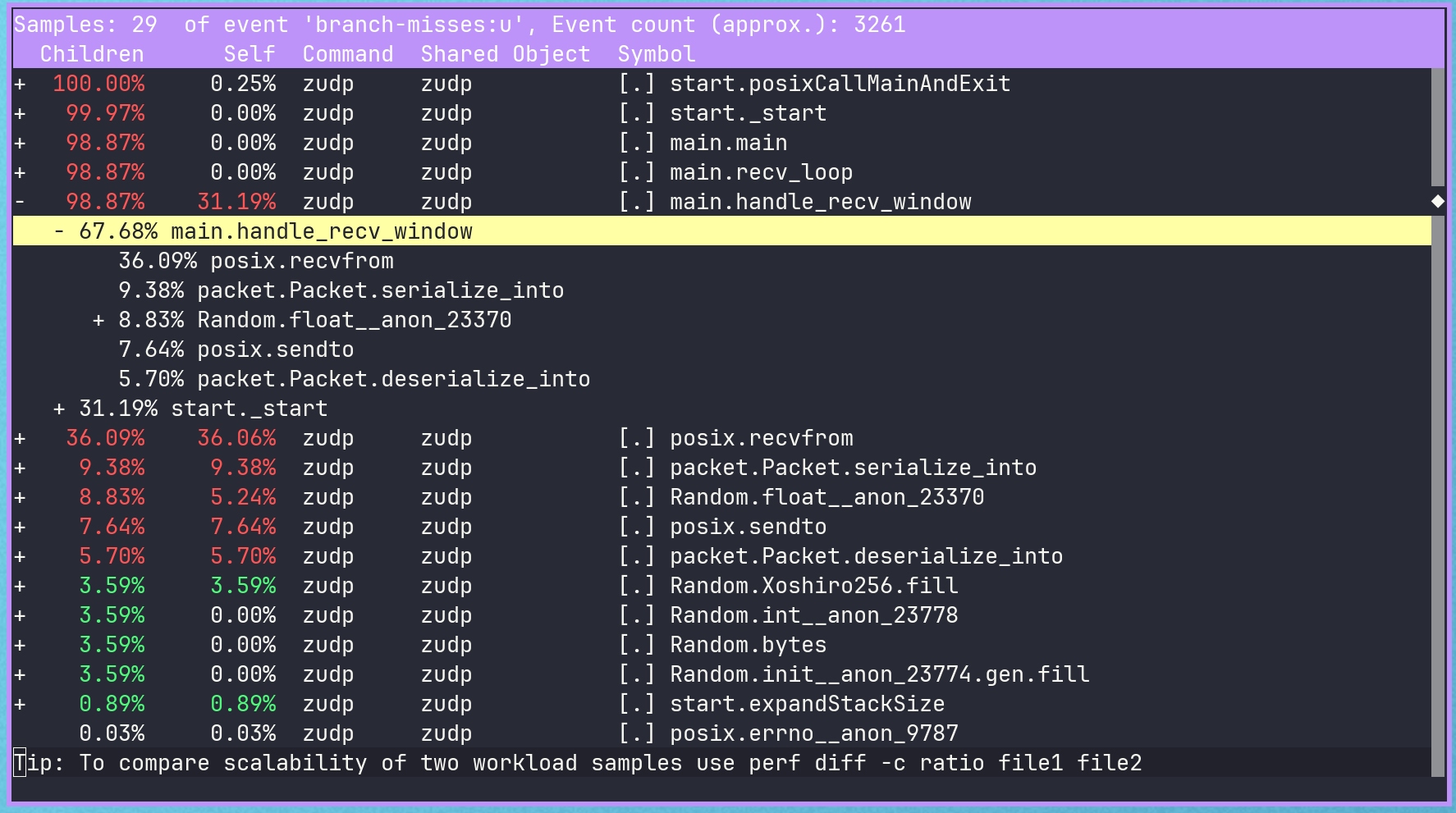
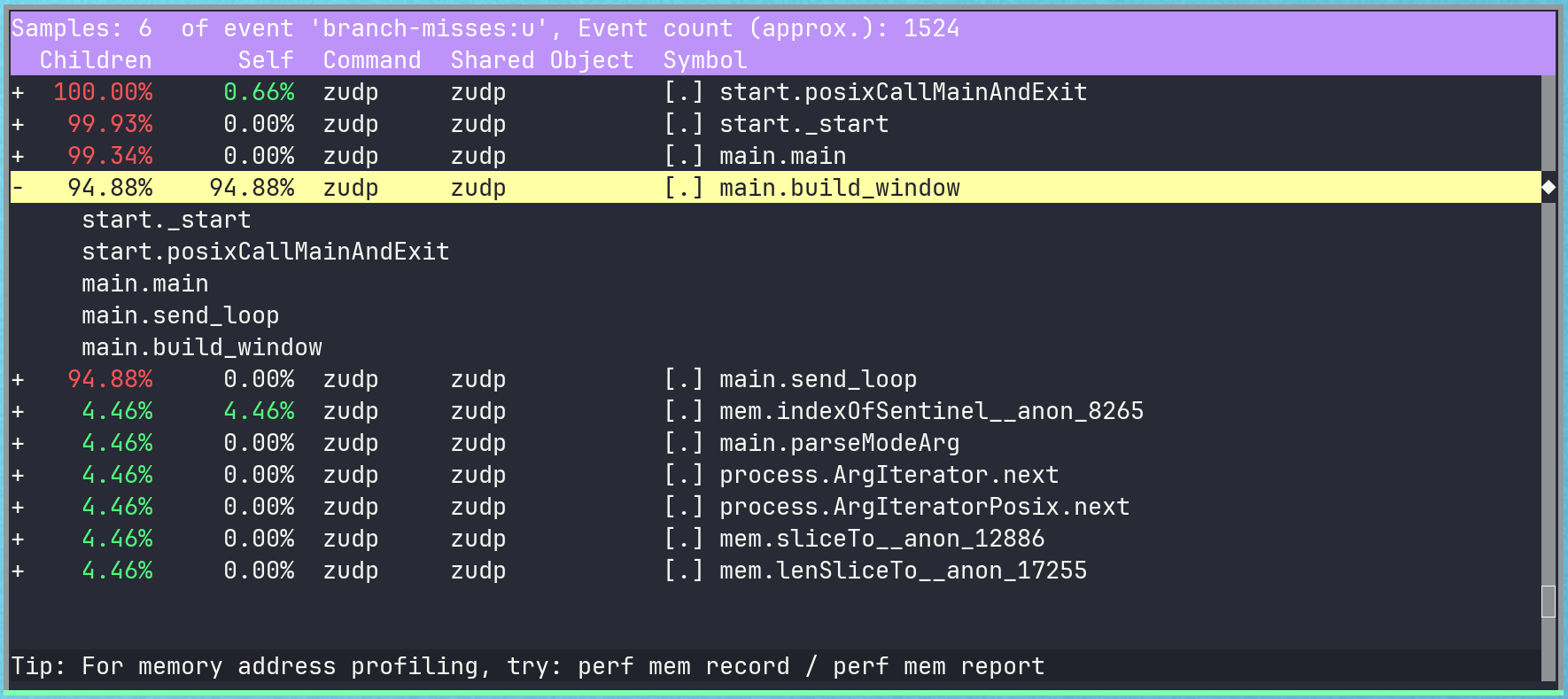
This is because of the switch statements on packet kinds, the buffer overflow check, and accessing of different fields on the packet struct itself based on the kind. All of these can causes misses due to improper prediction of the packet kind and lack of CPU cache locality.
Branch Hints
We can make use of the builtin @branchHint to signal to the compiler optimizer which branches are most likely to be hit. We can use likely, unlikely, and cold for Data, Ack, EoT in that order.
@branchHint(.likely);
Note that in most cases you should not be using @branchHint. Take care to avoid peppering @branchHint calls throughout your code.
Generally, @branchHint should only be used when you have code where the most commonly taken path appears later in the ordering than other options. For example, in our send_window function, we know that the code should most commonly reply to client Data packets with Ack responses. @branchHint is appropriate here if we inspect the generated machine code and notice that the jump instruction for the Ack branch is ordered after the jump instructions for other packet kinds.
If we just naively set @branchHint to likely for Data in a few places, from the original ’end of part 2’ stats this gets us to the following.
Sender:
Performance counter stats for './zig-out/bin/zudp -- --mode send':
314,253 branches:u
5,988 branch-misses:u # 1.91% of all branches
0.729944272 seconds time elapsed
0.001998000 seconds user
0.001865000 seconds sys
Receiver:
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
259,331 branches:u
4,456 branch-misses:u # 1.72% of all branches
1.286257771 seconds time elapsed
0.001009000 seconds user
0.002082000 seconds sys
Jump Table
Another option for eliminating the switch statement is a function pointer jump table. Here we’re defining separate serialization and deserialization functions for each packet type, but only for the bits that are not common to other packet types. We then create a ‘jump table’ of function pointers, where the index into an array (for the same index -> enum value as our packet Kind enums) gives us a function pointer to the serialization/deserialization function for that packet type.
This kind of code level jump table likely won’t make much of a difference in our case as:
- We have very few cases in our switch statement and, since we’re switching on the enum tagged union, Zig knows our switch statement has to be exhaustive of all the options.
- With only a few possible cases, the compiler may decide that it’s more efficient to use a series of compare-and-jump instructions rather than generating its own jump table. This is because the overhead of indexing into a table may exceed the cost of sequential comparisons for small case counts.
Later we’ll compare the Jump Table and other results with simply passing -O ReleaseSafe (which we have not been using so far) at build time.
With this change the branch misses are essentially the same across a few runs as we had with the @branchHint change across multiple runs:
Sender:
Performance counter stats for './zig-out/bin/zudp -- --mode send':
322,202 branches:u
6,355 branch-misses:u # 1.97% of all branches
0.724617972 seconds time elapsed
0.000876000 seconds user
0.002310000 seconds sys
Receiver:
Total allocated: 0, Total allocations: 0, Current usage: 0, Max usage: 0
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
266,677 branches:u
4,464 branch-misses:u # 1.67% of all branches
1.774271352 seconds time elapsed
0.000000000 seconds user
0.004086000 seconds sys
This pattern is relatively uncommon for me to see, at least over the last few years of only using Go, so I’ll keep it over @branchHint (in addition to the caveats about using @branchHint).
Building with -Doptimize=ReleaseSafe
Until now we haven’t been passing any option for compiler optimization. If we go back to the stats at the end of the packet sizing section, we have 40-60k branches/1.4-1.8k misses for the sender, and 29-34k branches/1-1.2k misses for the receiver.
Combining the packet size changes with either the function pointer + jump table or @branchHint changes didn’t make any noticeable additional improvements. We see inconsistent results in the perf record results in terms of which of our functions crop up as branch misses, which means we could just be chasing a red herring. Rather than chasing more optimizations via changing our own code, we can pass some optimization flags at build time. We’ll compare this to earlier commits as well such as the original code + ReleaseSafe.
Sender with ReleaseSafe:
Performance counter stats for './zig-out/bin/zudp -- --mode send':
19,540 branches:u
949 branch-misses:u # 4.86% of all branches
0.518633490 seconds time elapsed
0.000774000 seconds user
0.000000000 seconds sys
Receiver with ReleaseSafe:
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
8,915 branches:u
1,005 branch-misses:u # 11.27% of all branches
14.064418832 seconds time elapsed
0.001436000 seconds user
0.000433000 seconds sys
If we checkout the commit from the end of part 2 and build with ReleaseSafe we get:
Sender:
Performance counter stats for './zig-out/bin/zudp -- --mode send':
90,067 branches:u
3,773 branch-misses:u # 4.19% of all branches
0.515746284 seconds time elapsed
0.000000000 seconds user
0.002891000 seconds sys
Receiver:
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
54,717 branches:u
2,164 branch-misses:u # 3.95% of all branches
1.235975611 seconds time elapsed
0.002364000 seconds user
0.000000000 seconds sys
A good reminder, don’t optimize without realistic data. We could have got nearly all the way to our most optimized version by just passing the right build time flags.
Conclusion
This exploration of branch optimization in Zig revealed several important lessons:
Manual optimization has diminishing returns: While techniques like direct bit manipulation, unsafe enum conversions, and branch hints provided measurable improvements, the biggest gains came from higher-level changes like packet sizing and compiler optimization flags.
Measure first, optimize second: Trying to optimize against a debug build is a silly mistake. Simply adding -Doptimize=ReleaseSafe provided 60-80% branch miss reduction with minimal code changes. This reinforces the importance of establishing realistic performance baselines before pursuing micro-optimizations.
Context matters: The ~75% branch miss reduction from larger packets demonstrates that sometimes the best optimization is changing the problem parameters rather than optimizing the solution.
For production applications, the hierarchy of optimization effort should be:
- compiler flags
- algorithmic improvements or general data flow changes (like packet sizing)
- targeted manual optimizations where profiling shows clear bottlenecks
Next Steps
In Part 3, we’ll implement the full sliding window protocol with proper timeout handling, allowing the receiver to process partial windows and handle out-of-order delivery more gracefully.
The focus will shift from micro-optimizations to protocol correctness and real-world usability.