Recap
In part one, we implemented a minimal Reliable UDP in Zig.
In this post, we extend the sender with a window size. This isn’t a full sliding window yet. For now, we buffer multiple packets and treat an ACK for a higher sequence number as acknowledging all preceding packets in the window.
For example, if the last ACK was for sequence #4, our window size is 5, and we send #5–9, receiving an ACK for #7 means packets #5–7 are acknowledged.
This reduces overhead by avoiding per-packet ACKs and the network congestion that can come with them. In this demo, the effect is small, but in real-world applications, it can matter.
Reminder that the code here is using zig 0.15.
Window Structure
First we’ll define the structure for our window.
pub const PacketWindow = struct {
buffer: [window_size]Packet,
base_seq: u32 = 0, // sequence number of first (oldest) packet
next_seq: u32 = 0, // next to be generated
count: usize = 0,
head: usize = 0, // write position (mod N)
pub fn initalize(self: *PacketWindow, allocator: *tracking_allocator.TrackingAllocator) !void {
for (&self.buffer) |*pkt| {
pkt.* = .{
.src = undefined,
.dest = undefined,
.kind = .{ .Data = .{
.seq = 0,
.len = 0,
.data = try allocator.alloc(u8, 1024 - 21),
} },
};
}
}
};
In this example, the window is used only for sending Data packets, so we set it up via the initialize function.
The head tracks the index of the lowest sequence number in the window. Combined with count and the modulo operator (%), it lets us determine both where to insert the next packet and the order in which to send packets.
For example, the function to push a new packet to the window looks like this:
pub fn push_data(self: *PacketWindow, data: PacketData) !void {
if (self.count >= window_size) {
return error.WindowFull;
}
const expected_seq = self.base_seq + self.count;
if (self.next_seq != expected_seq) {
return error.UnexpectedSequence;
}
const insert_index = (self.head + self.count) % window_size;
var pkt = &self.buffer[insert_index];
var kind_data = &pkt.kind.Data;
// do the insert
pkt.src = data.src;
pkt.dest = data.dest;
kind_data.seq = data.seq;
std.mem.copyForwards(u8, kind_data.data, data.data);
self.count += 1;
self.next_seq += 1;
}
Suppose the window_size is 5 (indices 0–4). If head is 3 and count is 2, that means indices 3 and 4 hold unacknowledged packets. Using (3 + 2) % 5 = 0, the next incoming packet goes into index 0.
Note that we’re not going to actually allocate new packets; instead, we overwrite fields in the existing packet structures. This keeps memory usage bounded to max packet size * window size and avoids repeated allocations. It also allows us to only deal with freeing memory once. While an arena allocator could do the same, the low allocation frequency makes it unnecessary. Passing the data to push_data also lets us reuse a single buffer for file reading with std.mem.copyForwards into each packet.
Next we have the windows ack function, which handles the earlier behaviour of the receiver acknowledging multiple packets at once:
// Slide window forward on ACK (inclusive)
pub fn ack(self: *PacketWindow, ack_seq: u32) void {
if (ack_seq + 1 < self.base_seq) {
std.debug.print("old ack", .{});
// Older ACK, ignore
return;
}
const acked = ack_seq + 1 - self.base_seq;
if (acked > self.count) {
std.debug.print("too new ack", .{});
// ACK beyond current window, ignore or handle error
return;
}
const N = self.buffer.len;
self.head = (self.head + acked) % N;
self.base_seq = ack_seq + 1;
self.count -= acked;
}
Finally we have two little helper functions:
pub fn can_push(self: *PacketWindow) bool {
return self.count < self.buffer.len;
}
pub fn deinit(self: *PacketWindow, allocator: *tracking_allocator.TrackingAllocator) void {
// We need &self.buffer and *pkt so that we don't get a const reference to each packet.
for (&self.buffer) |*pkt| {
pkt.deinit(allocator);
}
}
can_push lets the file-reading code from part 1 skip reading or pushing a packet when the window is full.
Similarly deinit simply calls packet.deinit for every packet in the window. In part 1 we already wrote packet.deinit to handle freeing the u8 buffer used by Data packets.
Packet updates
One small addition to the packet code from part 1 is the deserialize_data function on the packet struct:
pub fn deserialize_data(self: *Packet, bytes: []u8) !void {
var stream = std.io.fixedBufferStream(bytes);
var r = stream.reader();
const src_bytes = try r.readBytesNoEof(4);
const src_port = try r.readInt(u16, .little);
self.src = std.net.Ip4Address.init(src_bytes, src_port);
const dest_bytes = try r.readBytesNoEof(4);
const dest_port = try r.readInt(u16, .little);
self.dest = std.net.Ip4Address.init(dest_bytes, dest_port);
const kind_byte = try r.readByte();
const kind_tag: PacketType = try std.meta.intToEnum(PacketType, kind_byte);
if (kind_tag != .Data)
return error.UnexpectedPacketType;
const data = &self.kind.Data;
data.seq = try r.readInt(u32, .little);
const len: usize = try r.readInt(u32, .little);
if (len > data.data.len) {
// std.debug.print("len: {d} data len {d}\n", .{ len, data.data.len });
return error.DataBufferTooSmall;
}
data.len = len;
try r.readNoEof(data.data[0..len]);
}
This lets our example receiver deserialize incoming bytes directly into an existing packet struct, avoiding extra memory allocations. The same approach works on the sender when processing ACK packets.
Tracking Allocator
While working on part 2, I wanted an easy way to track improvements from memory reuse techniques. I know std.heap.DebugAllocator exists, but I wanted to monitor the number of allocations, max in use allocated bytes, and total bytes allocated.
I’m still getting used to Zig’s vtable struct pattern, which lets our TrackingAllocator act as a std.mem.Allocator. Getting Go’s interface syntax out of my head and remembering that I have to specify which functions on the vtable we’re overwriting will take a minute to get used to.
pub const TrackingAllocator = struct {
base_allocator: std.mem.Allocator,
total_allocated: usize = 0,
total_allocations: u32 = 0,
current_allocated: usize = 0,
max_allocated: usize = 0,
pub fn init(a: std.mem.Allocator) TrackingAllocator {
return TrackingAllocator{ .base_allocator = a };
}
fn rawAlloc(ctx: *anyopaque, len: usize, alignment: std.mem.Alignment, ra: usize) ?[*]u8 {
const self: *TrackingAllocator = @ptrCast(@alignCast(ctx));
const mem = self.base_allocator.rawAlloc(len, alignment, ra) orelse return null;
self.total_allocated += len;
self.total_allocations += 1;
self.current_allocated += len;
if (self.current_allocated > self.max_allocated) {
self.max_allocated = self.current_allocated;
}
return mem;
}
fn rawResize(ctx: *anyopaque, old_mem: []u8, alignment: std.mem.Alignment, new_len: usize, ra: usize) bool {
const self: *TrackingAllocator = @ptrCast(@alignCast(ctx));
const success = self.base_allocator.rawResize(old_mem, alignment, new_len, ra);
if (!success) return false;
const old_len = old_mem.len;
if (new_len > old_len) {
const diff = new_len - old_len;
self.total_allocated += diff;
self.current_allocated += diff;
} else {
self.current_allocated -= old_len - new_len;
}
if (self.current_allocated > self.max_allocated)
self.max_allocated = self.current_allocated;
return success;
}
fn rawFree(ctx: *anyopaque, mem: []u8, alignment: std.mem.Alignment, ra: usize) void {
const self: *TrackingAllocator = @ptrCast(@alignCast(ctx));
self.current_allocated -= mem.len;
self.base_allocator.rawFree(mem, alignment, ra);
}
fn rawRemap(
ctx: *anyopaque,
old_mem: []u8,
alignment: std.mem.Alignment,
new_len: usize,
ra: usize,
) ?[*]u8 {
const self: *TrackingAllocator = @ptrCast(@alignCast(ctx));
return self.base_allocator.rawRemap(old_mem, alignment, new_len, ra);
}
pub fn allocator(self: *TrackingAllocator) std.mem.Allocator {
return std.mem.Allocator{
.ptr = self,
.vtable = &.{
.alloc = rawAlloc,
.resize = rawResize,
.free = rawFree,
.remap = rawRemap,
},
};
}
};
Of course, this only tracks memory allocated by the Allocator itself.
Sender Changes
The main changes on the sending side are around handling reading into and sending packets from the window as opposed to one packet per loop iteration:
var file = try std.fs.cwd().openFile("book.txt", .{});
defer file.close();
var window = packet.PacketWindow{
.buffer = undefined,
.base_seq = 0,
.count = 0,
.head = 0,
};
try window.initalize(allocator);
defer window.deinit(allocator);
while (true) {
build_window(&window, file) catch |err| switch (err) {
error.ErrotEoT => {
if (window.count == 0) {
break;
}
},
else => return err,
};
const ack = send_window(sock, window) catch |err| switch (err) {
error.NoAck => continue,
else => return err,
};
window.ack(ack);
if (window.count != 0) {
continue;
}
}
The call to window.ack will slide the window forward so we don’t have to retry sends directly in each loop iteration anymore.
The build_window function uses the previously mentioned can_push function to fill the window with packets. It handles overwriting already ACK’d packets:
fn build_window(window: *packet.PacketWindow, f: std.fs.File) !void {
var buf: [1024 - 21]u8 = undefined;
while (true) {
if (!window.can_push()) {
return;
}
const bytesRead = try f.read(buf[0..]);
if (bytesRead == 0) {
return error.ErrotEoT; // EOF reached
}
window.push_data(.{ .src = sender.in, .dest = receiver.in, .seq = @intCast(window.next_seq), .data = buf[0..bytesRead] }) catch break;
}
}
Then we simply send the window’s packets and wait for an ACK.
fn send_window(sock: std.posix.socket_t, window: packet.PacketWindow) !u32 {
for (0..window.count) |i| {
const index = (window.head + i) % window.buffer.len;
const pkt = window.buffer[index];
const n = try pkt.serialize(@constCast(&send_buffer));
_ = try std.posix.sendto(sock, send_buffer[0..n], 0, @ptrCast(&receiver.any), receiver.getOsSockLen());
}
var buf: [1024]u8 = undefined;
const recv_len = std.posix.recvfrom(sock, @constCast(&buf), 0, null, null) catch |err| switch (err) {
error.WouldBlock => { // Would block is how the timeout is represented for recvfrom.
std.debug.print("Timeout waiting for ack, retrying...\n", .{});
return error.NoAck;
},
else => return err,
};
const pkt_recv = try packet.Packet.deserialize(buf[0..recv_len]);
switch (pkt_recv.kind) {
.Ack => |ack| {
return ack.ack;
},
else => std.debug.print("Unexpected packet received while waiting for ack\n", .{}),
}
return error.NoAck;
}
Receiver Changes
Again most of the changes are simply related to handling the window rather than individual packets.
while (true) {
handle_recv_window(sock, &expected_seq) catch |err| switch (err) {
error.ErrotEoT => {
std.debug.print("got an eot", .{});
return;
},
else => return err,
};
}
handle_recv_window loops until window_size packets (in sequence # order) are received.
while (recv_count < packet.window_size) {
const ret = posix.recvfrom(sock, @constCast(&recv_buf), 0, &addr, &addr_len) catch |err| switch (err) {
error.WouldBlock => {
// We haven't received anything yet, so nothing to ACK.
if (highest_seq_seen == null) {
continue;
}
break;
},
else => return err,
};
it += 1;
if (ret == 0) {
// This shouldn't be possible since the socket is blocking, but lets just be safe.
continue;
}
recv_count += 1;
const kind = try packet.check_kind(&recv_buf);
switch (kind) {
.Data => {
try pkt.deserialize_data(&recv_buf);
r = pkt.dest;
s = pkt.src;
if (pkt.kind.Data.seq == expectedSeq.*) {
std.debug.print("{s}", .{pkt.kind.Data.data[0..pkt.kind.Data.len]});
highest_seq_seen = pkt.kind.Data.seq;
expectedSeq.* += 1;
} else {
// Out of order packet — ignore or handle according to your protocol/application needs.
}
},
.Ack => {
// Ignore incoming ACKs here if you want
},
.EoT => {
// we should ACK here and exit
std.debug.print("\n", .{});
return error.ErrotEoT;
},
}
}
As mentioned, since Zig currently lacks select, I’ll defer a full sliding window implementation to the next post. A correct version would let the receiver handle Data packets without needing to know the window size, simply receiving packets for a period (or up to the window size, communicated via handshake or packet field) before timing out and sending an ACK.
The commit for the code at this point is here.
Memory Usage and Performance Insights

Note: This section is fairly basic for experienced systems developers, but it was enjoyable for me since I haven’t used tools like perf or valgrind in a while.
Tracking Allocator
First we can look at the output from our tracking allocator. Note that all calls to an allocator have been removed for the receiver path, so for now we’re just looking at the sender.
Total allocated: 6039, Total allocations: 6, Current usage: 0, Max usage: 6039
The packet window size is defined as 5 so that accounts for 5/6 allocations.
pub const window_size = 5;
For our packet definition, each Data packet has a header overhead of 21 bytes, so when we allocate the data buffer for those we’re actually allocating 1024-21 = 1003 bytes each. That accounts for 5015 bytes, meaning we have another 1024 allocated somewhere.
The only other alloc call on the senders path is for the EoT packets serialization.
const buffer = try allocator.alloc(u8, 1024);
This obviously doesn’t need to be allocating 1K for an EoT packet. We only have a header overhead of 13 bytes for an EoT packet, so we can just change that value.
Total allocated: 5028, Total allocations: 6, Current usage: 0, Max usage: 5028
Though we can actually remove that 6th allocation. ATM the pre-defined EoT packet is using a separate buffer for it’s serialization when we remove this we get down to only the window related allocations.
Total allocated: 5015, Total allocations: 5, Current usage: 0, Max usage: 5015
Branch Misses
One way to hurt your program’s CPU performance is adding many branches, increasing branch misprediction. Let’s see if we can fix that.
On the happy path, our sender looks like this:
Performance counter stats for './zig-out/bin/zudp -- --mode send':
4,731,433 branches:u
10,029 branch-misses:u # 0.21% of all branches
0.530626336 seconds time elapsed
0.000000000 seconds user
0.006419000 seconds sys
This seems okay in terms of miss percentage, how about the receiver?
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
1,403,209 branches:u
16,642 branch-misses:u # 1.19% of all branches
1.071376226 seconds time elapsed
0.002953000 seconds user
0.013757000 seconds sys
Still not too much, but a lot more misses relative to the sender. Let’s see what we can find.
We can use perf record -e branches,branch-misses -g <program> to record the branch info. and then use perf report to view it.
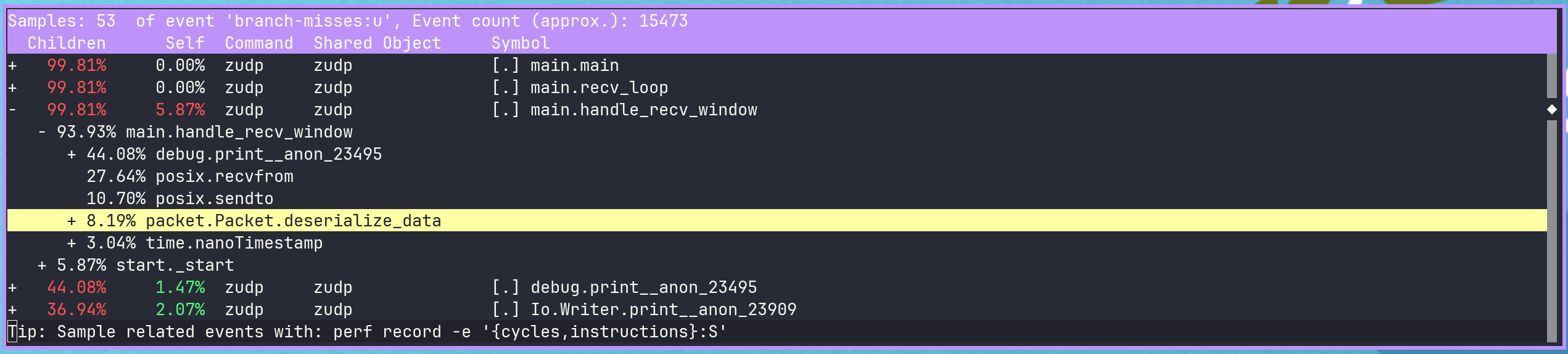
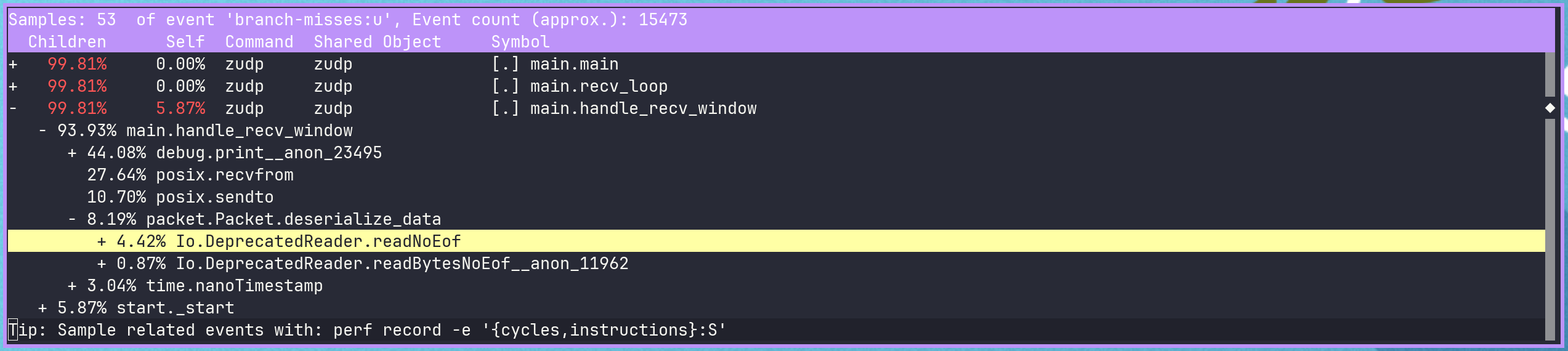
In the report we can see that a decent chunk of the misses are coming from the usage of the FixedBufferStream/reader readNoEof function within deserialize_data.
We only explicitly call that function three times in deserialize_data, but the stream’s reader also calls readNoEof internally for every readInt (current zig deprecated reader).
FixedBufferStream type is deprecated, Deprecated in favor of std.Io.Reader.fixed and std.Io.Writer.fixed., but this is a good chance to use bit shifting:
- Packet definitions are under our control.
- We only deserialize one (or a few) packet types.
- Serialization is always little-endian.
- Wire bytes are already provided as a slice
deserialize_data now looks like this:
pub fn deserialize_data(self: *Packet, bytes: []u8) !void {
self.src = std.net.Ip4Address.init(bytes[0..4].*, @as(u16, bytes[4]) | (@as(u16, bytes[5]) << 8));
self.dest = std.net.Ip4Address.init(bytes[6..10].*, @as(u16, bytes[10]) | (@as(u16, bytes[11]) << 8));
const kind_byte = bytes[12];
const kind_tag: PacketType = try std.meta.intToEnum(PacketType, kind_byte);
if (kind_tag != .Data)
return error.UnexpectedPacketType;
const data = &self.kind.Data;
data.seq = @as(u32, bytes[13]) |
(@as(u32, bytes[14]) << 8) |
(@as(u32, bytes[15]) << 16) |
(@as(u32, bytes[16]) << 24);
const len: usize = @as(u32, bytes[17]) |
(@as(u32, bytes[18]) << 8) |
(@as(u32, bytes[19]) << 16) |
(@as(u32, bytes[20]) << 24);
if (len > data.data.len) {
return error.DataBufferTooSmall;
}
data.len = len;
data.data = bytes[21 .. 21 + len];
}
We probably want to guard some more against insufficient length slices in production code, but less see what perf says now.
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
682,833 branches:u
13,723 branch-misses:u # 2.01% of all branches
3.238406723 seconds time elapsed
0.001842000 seconds user
0.015572000 seconds sys
Nice, about half as many branches overall and slightly fewer misses.
Now perf output shows that most branch misses came from printing packet data. We’ll comment out that line to focus on more important optimizations. In production, if persistence of incoming data mattered, we’d accept the memory cost of buffering more data rather than flushing to a file too frequently. The same approach could later be applied to stderr printing if we cared to do so.
Another contributor is the RNG used to decide packet drops. We can reduce its impact by moving the generator initialization to recv_loop, avoiding a std.time.nanoTimestamp() call per packet.
The recevier perf output now looks like this:
Performance counter stats for './zig-out/bin/zudp -- --mode recv':
377,933 branches:u
4,137 branch-misses:u # 1.09% of all branches
2.334070233 seconds time elapsed
0.001466000 seconds user
0.002930000 seconds sys
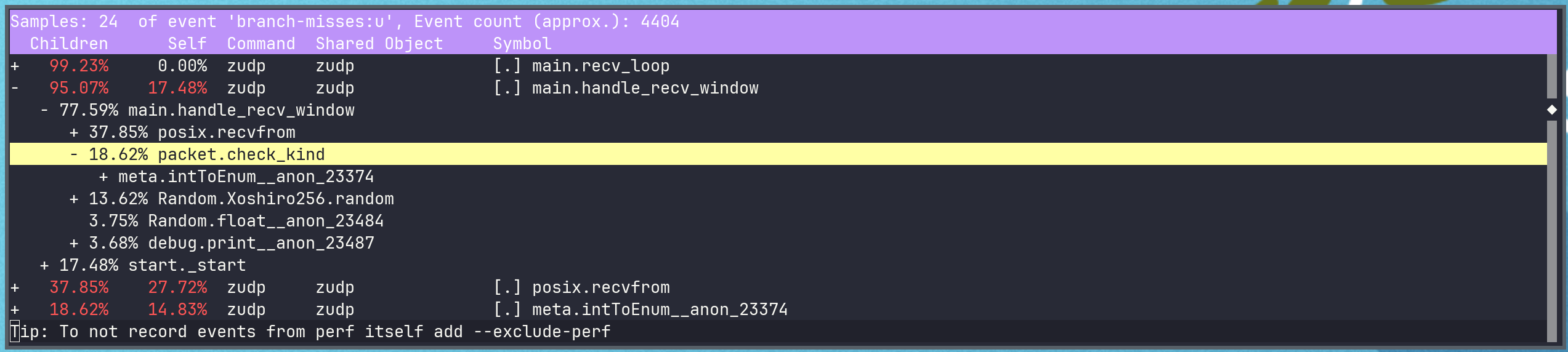
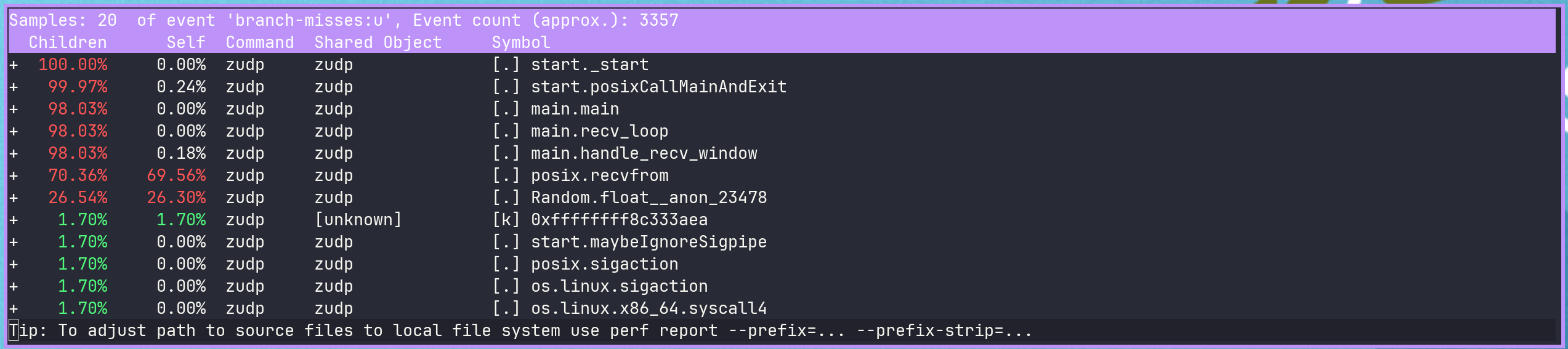
Now we see that overall most of the misses are just for the socket’s recvfrom call. However, a decent chunk is also from the check_kind call, after which we have a switch statement.
We can use @enumFromInt in places we need to keep switch statements on the packet kind, which is unsafe if the integer value is not valid for the enum.
const kind: packet.PacketType = @enumFromInt(recv_buf[12]);
switch (kind) {
.Data => {
// the same code as before
},
.Ack => {
// Ignore incoming ACKs here if you want
},
.EoT => {
// we should ACK here and exit
std.debug.print("\n", .{});
return error.ErrotEoT;
},
}
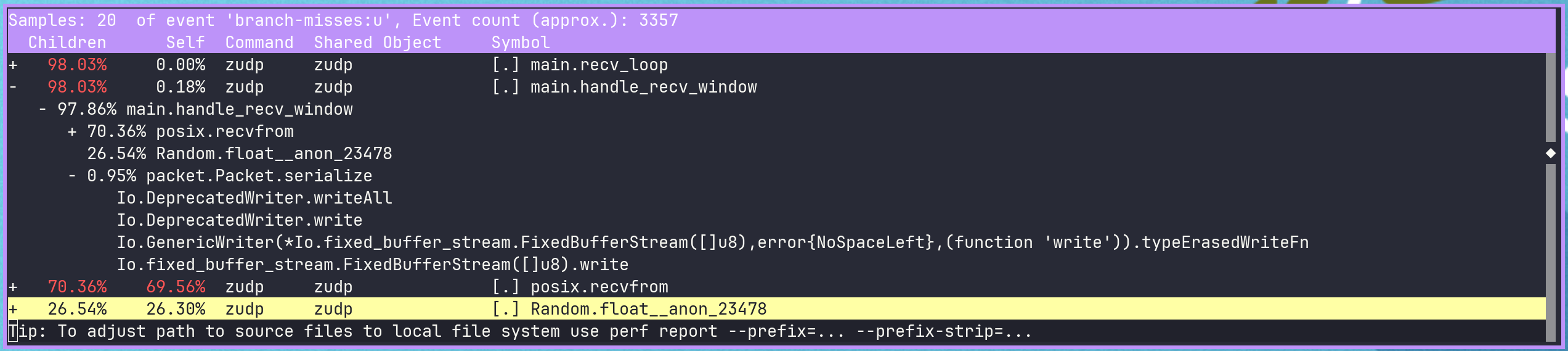
We now have essentially no misses on the receievers path that are not either from debug logging, the RNG, or recvfrom.
Lets look more at the sender, almost all of it’s misses are in our serialize and deserialize functions.
Lets start by turning serialize into serialize_data and also handle the ack case. Lets rename it to serialize_into as well.
4,646,337 branches:u
8,356 branch-misses:u # 0.18% of all branches
1.140326874 seconds time elapsed
0.006188000 seconds user
0.000913000 seconds sys
Most of our branches come from std.mem.copyForwards in push_data, which the stdlib marks as deprecated in favor of the @memmove builtin. About 11% of branches also come from packet serialization.
We’ll switch to @memmove (or @memcpy, since the slices here don’t overlap). Keep in mind that these builtins require the source and destination slices to have equal lengths.
@memmove(kind_data.data[0..data.data.len], data.data);
886,572 branches:u
7,639 branch-misses:u # 0.86% of all branches
0.521193266 seconds time elapsed
0.000000000 seconds user
0.004463000 seconds sys
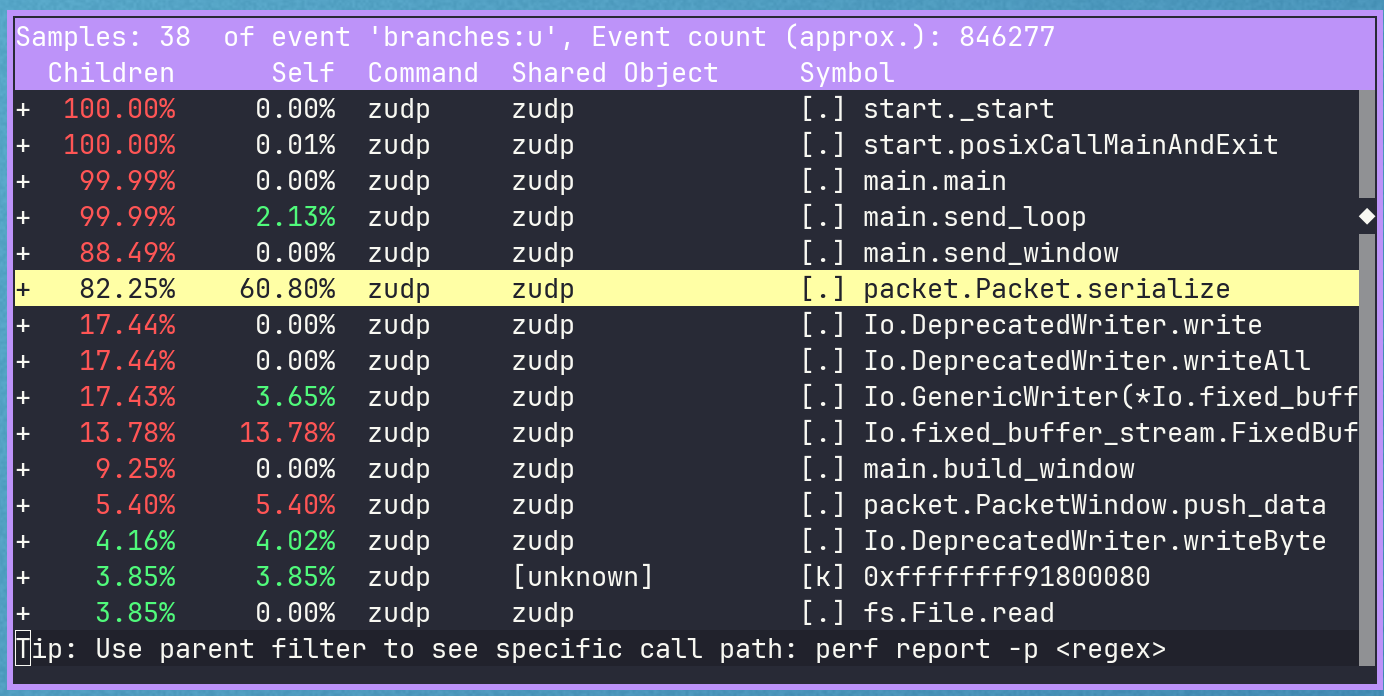
Much better. The remaining obvious optimization is in the serialization function, which now accounts for ~60% of total branches. We can simplify it like we did for deserialization, avoiding the deprecated writer types.
pub fn serialize_into(self: *const Packet, buffer: []u8) !usize {
var i: usize = 0;
if (buffer.len < 13) return error.BufferTooSmall;
buffer[0] = @truncate(self.src.sa.addr >> 0);
buffer[1] = @truncate(self.src.sa.addr >> 8);
buffer[2] = @truncate(self.src.sa.addr >> 16);
buffer[3] = @truncate(self.src.sa.addr >> 24);
buffer[4] = @truncate(self.src.sa.port >> 0);
buffer[5] = @truncate(self.src.sa.port >> 8);
buffer[6] = @truncate(self.dest.sa.addr >> 0);
buffer[7] = @truncate(self.dest.sa.addr >> 8);
buffer[8] = @truncate(self.dest.sa.addr >> 16);
buffer[9] = @truncate(self.dest.sa.addr >> 24);
buffer[10] = @truncate(self.dest.sa.port >> 0);
buffer[11] = @truncate(self.dest.sa.port >> 8);
buffer[12] = @intFromEnum(self.kind);
i = 13;
switch (self.kind) {
.Data => |d| {
if (buffer.len < 21 + d.data.len) return error.BufferTooSmall;
buffer[13] = @truncate(d.seq >> 0);
buffer[14] = @truncate(d.seq >> 8);
buffer[15] = @truncate(d.seq >> 16);
buffer[16] = @truncate(d.seq >> 24);
buffer[17] = @truncate(d.data.len >> 0);
buffer[18] = @truncate(d.data.len >> 8);
buffer[19] = @truncate(d.data.len >> 16);
buffer[20] = @truncate(d.data.len >> 24);
@memcpy(buffer[21 .. 21 + d.data.len], d.data);
i += 8 + d.data.len;
},
.Ack => |a| {
buffer[13] = @truncate(a.ack >> 0);
buffer[14] = @truncate(a.ack >> 8);
buffer[15] = @truncate(a.ack >> 16);
buffer[16] = @truncate(a.ack >> 24);
i += 4;
},
.EoT => std.debug.print("serialized EoT", .{}),
}
return i;
}
Now we have:
391,758 branches:u
7,316 branch-misses:u # 1.87% of all branches
1.350311334 seconds time elapsed
0.001164000 seconds user
0.003624000 seconds sys
Conclusion
That’s good enough for now. Using std.mem.readInt and writeInt would have been nice, but the net address fields make converting between u32 and []u8 messy.
In the next post we’ll finalize the sliding window by buffering more than window_size packets and letting the receiver handle partial windows via a timeout in handle_recv_window.
The final code for this post is here.